The previous chapter discusses
viewers.
Repositories
A repository simply provides "electronic paper"
on which authors may publish information which
users may subsequently read. A repository collects
fees from both authors and users in the form of
monthly storage fees and royalties, respectively.
Collected royalty fees are split between the
repository and the author. Since different
repositories will have differing fee structures,
authors will tend to shop around until they find
the fee structure that they are most comfortable
with.
Storage Formats
The repository fundamentally stores and retrieves
bit strings. While, in general, the format used to
represent the author's information is of no
consequence to the repository, the viewer software
will need to know the representation in order to
meaningfully render it to the user. Thus, the
repository must provide mechanisms for allowing
the viewer software to identify the format of
information that is being retrieved. In addition,
for some storage formats, the viewer software,
cache, and repository will provide algorithms that
optimize how information is transmitted across the
network (e.g. images, audio, etc.)
While authors will initially use existing
information storage formats, over time, new
formats and transmission strategies will
evolve to minimize storage and optimize
transmission bandwidth. Each of the standard
information formats is discussed below:
-
Text
-
Text will initially use standards such as
ASCII, Latin-1, and Unicode. Future formats
are likely to be based on Huffman encodings
of characters, words, and/or phrases.
Lempf-Zempel compression algorithms are likely
to be utilized between viewer, cache, and
repository to optimize network bandwidth.
Most textual information has more structure
than just a linear sequence of words (e.g.
paragraph breaks, enumeration lists, headings,
footnotes, cross-references, etc.) Some standard
will be needed to encode this formatting
information. It is desirable that the standard
preserve the ability to make hypertext links to
sub-spans of text (see below about hypertext
links), let the reader select the font style
in which the text is to be rendered, and get
away from page oriented display (after all, this
new from of "electronic paper" that does not
really have the concept of the end of the page.)
Thus, while Postscript comes to mind almost
immediately, it is not a perfect match for the
desired standard.
-
Raw images.
-
Raw images have the following parameters -
height and width in pixels, bits per pixel,
and the pixel format (grey scale, red-green-blue,
etc.) The most typical way to store the pixels
is in left-to-right/top-to-bottom order. There
is no particular reason not to store an image
in a compressed format such as TIFF. If there
is sufficient network bandwidth between the
viewer software, cache, and repository, the viewer
software will uncompress the image itself; otherwise,
the repository (or cache) will uncompress the image
and send it to the viewer in a manor that more
effectively uses network bandwidth. For example,
if the viewer can only display 3-bits of each color,
only the high order three bits of each color in a
24-bit color image need to be transmitted. As a
further optimization, the pixel scanning order can
be changed from left-to-right/top-to-bottom to a
recursive quadrant order, whereby the image is
subdivided into successively smaller quadrants
until full resolution is achieved. The recursive
quadrant scan order for an 8-by-8 image is shown
below:
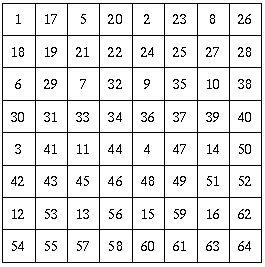
Using these two tricks, the viewer software will
be able to quickly render an image of acceptable
quality to the end-user even over relatively slow
modems.
-
Structured images
-
Structured images are either 2D or 3D images
whereby the image is described as a data
structure and/or rendering algorithm.
Postscript is an extremely popular 2D rendering
format and Phigs is a popular 3D format.
-
Audio
-
Audio has three basic parameters - the
number of channels (usually mono or stereo),
the number of bits per channel (usually 8 or
16 bits), and the sample frequency (usually
somewhere in the vicinity of 44 KHz.) Audio is
amendable to quite a bit of compression. As long
as hypertext links to spans of audio are still
possible, there is no reason not to store and
transmit the information in a compressed format.
A single channel of voice grade audio can be
transmitted in real-time using a linear adaptive
encoding via a 2400 baud connection.
-
Video
-
Video is likely to be stored in MPEG
format and its follow-on formats. The network
will have to have substantial bandwidth
improvements before real-time video becomes a
reality.
As technology evolves, new formats will be created.
Documents
The fundamental unit of publication is the document.
As far at the repository is concerned, a document is
merely a linear sequence of consecutive bits. However,
some structure and standards need to be imposed on
documents in order for viewer software to successfully
display the document to the user; these standards must
be extensible enough to deal with future innovation.
The first portion of the document is an attribute-value
list which lists standard information about the document
as a sequence of attribute-value pairs. The information
the attribute value pairs is:
-
Author
-
A hypertext link to the author record.
-
Title Index Entry
-
A hypertext link to the title index entry.
-
Author Index Entry
-
A hypertext link back to the author index
entry.
-
Subject Index Entries
-
A hypertext link for each subject index entry.
-
External hypertext link table
-
A list of embedded external hypertext links.
-
Rendering table.
(More about documents go here.)
Royalties
An author can charge different royalty rates for
reading different portions of a document; varying
royalty rates are particularly useful for documents
that contain a mixture of text, images and audio.
Just as important, the author is free to change the
royalty rates over time. For example, a struggling
author might have to initially use low royalty rates,
but as the author becomes more widely read, the royalty
rates can be increased for all of the author's published
material. This means that the account overlays need to
be kept separate from the document proper and they must
be updatable.
Both deliberate and accidental copyright infringement
will occur with electronic publishing. Whenever two
repositories have two reasonably long copyrighted bit
spans that exactly match, there is a copyright
infringement problem. It is not the responsibility of
the repositories to identify copyright infringement;
instead, they may rely on other people to discover the
infringement problem. The procedures for resolving a
copyright infringement case should basically be as follows:
-
The two copyright owners need to be notified.
Sometimes they will be able to arrive at a
mutually agreeable solution.
-
If the copyright owners can not reach a
mutually agreeable solution, they can submit
their case to some form of arbitration.
-
As a last resort, the two owners can apply
for a judgement from the legal system.
One of the most common solutions to the problem
will be to assign royalties from both spans of
bits to the same account; with this solution the
true copyright owner gets the same royalties
independent of which repository someone fetches
the information from; this solution does not address
royalties lost before the infringement was discovered.
While an infringement case is being worked out, each
repository can set up a separate impound account for
the disputed material; afterwards, the money stored
in the impound accounts can be released to the
appropriate author.
The courts can demand that material be removed from
publication for libel reasons. This is accomplished
by marking the published material as being unavailable
whenever it is asked for.
Indices
The author/subject/title indices are specific instances
of an index. An index is broken into two related
documents - a search tree and an entry list. The
search tree is used to quickly search for information.
The entry list is what is actually displayed to the user.
An entry list is permitted to have more than one search
tree that points to it. A logical view of a contrived
index is shown below; as can be seen, the
access tree only consists of search keys arranged as a
balanced binary tree with pointers from each tree node
to the corresponding full entry in the entry list.
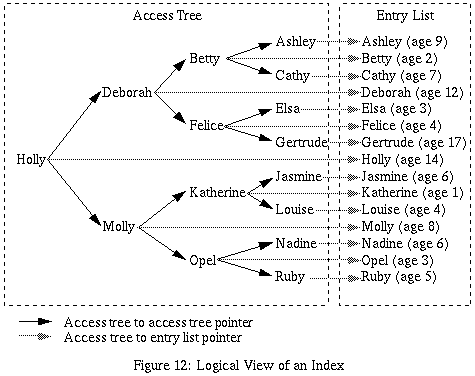
The search tree needs to be linearized into a document.
The primary concern during the linearization process is
to attempt to minimize the amount of I/O needed to search
down to a leaf node in the search tree. For example, if
the repository's most convenient blocking factor only
contains three tree nodes, the access tree in Figure 12
ould be linearized in triples as (Holly, Deborah, Molly),
(Betty, Ashley, Cathy), (Felice, Elsa, Gertrude),
(Katherine, Jasmine, Louise), and (Opel, Nadine, Ruby);
if, instead, the most convenient blocking factor is
seven to eight tree nodes, it would be linearized as
(Holly, Deborah, Molly, Betty, Felice, Katherine, Opel),
(Ashley, Cathy, Elsa, Gertrude, Jasmine, Louise, Nadine,
Ruby). When a search tree is published, the repository
should tell the publisher what the current blocking factor
is. Since as hardware evolves, the appropriate blocking
factor will change, the viewer software should not be
directly exposed to the actual blocking factor.
Since indices need to be updated over time, they are not
static. For example, the author/subject/title indices
need to be updated as new books are published. One strategy
is to store the access tree on read/write storage and
update the tree as new entries are added. An alternative
strategy is to publish an index as a sequence of
sub-indices that are searched as a whole; for this
strategy, an index might be updated weekly and every
quarter, the proceeding thirteen weeks would be
consolidated into a quarterly index, and every year
the proceeding three quarters would consolidated, etc.
A single search tree would be huge, but it still would
be quicker to search than searching a sequence of
smaller sub-trees. The advantage of having a number
of properly organized smaller search trees is that
they can reduce search time; conversely, if the trees
are organized incorrectly, they can increase search time.
Given that indices will be updated over time, it
probably makes sense to structure search trees as
2-3 trees so that standard tree balancing algorithms
can be applied. If search trees are only added to
and never deleted, it is possible to store them on
WORM (Write-Once/Read-Many) storage; otherwise,
indices need to be stored on read/write storage.
In practice, there will probably be a separate index
for each language (e.g. English, French, Spanish, etc.)
and each language index will updated over time.
Specialized Indices
Overlay hypertext links, masks,
and royalties are all implemented as indices. All of
these indices are use the repository numbers as the
first level key, followed by document number, finally
followed by a document offset.
The entry for an overlay hypertext link consists of
a textual descriptions (plus length) followed by an
embedded hypertext link. Whenever the viewer software
displays a span of text from a document, it will search
each of the hypertext overlays indices specified by the
user searching for hypertext links to display with the
text. If the user has specified M indices where each
index has an average of N entries, the search time will
be O(M log N). Most hypertext overlay indices will adopt
the convention of charging very little for reading the
hypertext link textual description and charging most of
the cost of traversing a hypertext link when the embedded
hypertext link is read.
Each mask entry specifies a document offset and length.
For restrictive masks, the viewer software will search
the mask tree to see whether there are any applicable
restrictions before actually displaying a text span.
For highlight masks, the masks can be searched after
the text span has been displayed.
Each royalty entry is specifies a document offset,
length, and royalty amount. Royalty entries are stored
in writable storage so that they be modified over time.
The Cache/Repository Protocol
The protocol between the cache and the repository
needs to support the following operations:
-
Start
-
Establish a connection between a
cache and a repository.
-
Read
-
Read a span of bits from the repository.
-
Royalty Query
-
Determine the royalty rate for a span of
bits from the repository.
-
Encoding Query
-
Determine what encoding is used for a span
of bits from the repository.
-
Deposit Money
-
Send an electronic check from the cache to
the repository.
-
Append
-
Publish a hypertext link onto the end
of a queue (used for mail and bulletin
boards.)
-
Finish
-
Shut down a connection between the cache
and the repository.
The first operation a cache performs is to establish a
connect with a repository. The cache needs to send an
electronic check to the repository to cover the costs
of other operations. The response back from the repository
is returned as an attribute value list which contains
information such as:
-
the cost per minute of being connected to the
repository,
-
the cost of requesting royalty information
,
-
etc.
The fundamental operation that viewer software performs
is the read operation. The read operation specifies a
document number, a starting bit offset, and the number
of bits to be fetched and returns a list of rate/sub-span
pairs; each When a cache receives a read request, it
first sees whether it can honor the request from its
local cache; if not, the cache establishes a connection
to the repository and forwards the request. Upon receiving
the request, the repository looks up the desired
information and returns it back to the cache. After
the request has been fulfilled, the appropriate amount
of royalty money is transferred from the cache account
to the appropriate author's account as described in the
section on electronic banking.
Since read requests may incur a royalty cost, there needs
to be a mechanism discovering the cost of information
before actually reading it. This is done by merely
querying the repositories royalty index.
Repository Hardware
Mass storage technology is currently undergoing a
tremendous rate of innovation. The reliability is
steadily increasing and the cost per bit is decreasing
dramatically. The amount and cost of storage available
via optical juke box technology is pretty amazing.
However, the access time for optical juke boxes is
sufficiently slow that they may not provide the
correct price performance ratio for a repository.
Repositories will require a great deal of network I/O
bandwidth. There needs to be enough network connections
to connect to each cache that needs access. Initial
repositories will need 10's to 100's of modems. It
does not take too much imagination to imagine a highly
utilized repository in the future having 1000's of
network connections.
Repositories will also require a great deal of storage
I/O bandwidth. Electronic publishing will only work if
the latency from the time that a user asks for information
until it shows up is measured in seconds. The way to
reduce latency is to cache commonly accessed information
in memory and spread the rest of the information across
a fairly large number of disk drives. By spreading the
information across a large number of drives, the average
request queue length for each drive should remain fairly
short.
While initial repositories will be able to get away
with implementations based on a single processor, as
they get larger, multiple processors will be required
to keep up with the vast amount of needed I/O. Ultimately
repositories may need specialize hardware for routing
an information request from the network connection to
the processor connected to the drive containing the
information. Thus, large repositories in the future may
have scaled down telephone switching networks to
interconnect the network connections to the information
storage devices.
You may read the next chapter discussing
caches or go back to the
table of contents.
Copyright 1992-1995
Wayne C. Gramlich All rights reserved.