This is one of my Web related projects. It is work in progress.
What is an annotation? An annotation is a comment on a document that is typically made by someone other than the original document author. Of particular importance to this paper is that the original author may not agree with the annotation.
For the purposes of this introduction, I have typed in the abstract of a paper entitled Transportation Economics of Extraterrestrial Resource Utilization by Andrew Hall Cutler and Mari Leilani Hughes. Using this abstract, I have inserted an example annotation into the abstract to show what an annotation might look like to an end user of an annotation system. Please follow the link to the paper abstract and the associated link to the annotation and then come on back here.
This document discusses a proposed architecture for a scalable annotation system for the World Wide Web. The purpose of this system is to allow people to attach annotations to pretty much any publicly available web page. While it is easy to design an annotation system that centralizes all of the annotations into a single centralized server, these centralized systems do not scale to support millions of simultaneous users. A scalable annotation system is one that is much more decentralized so that is can scale to millions of simultaneous users.
`Use the Web, Luke' is the design mantra utilized through out the design below. The Internet and World Wide Web have shown that they are scalable. Where ever possible I intend to use the existing Internet/Web protocols that have shown their ability to scale. Thus, for example, rather than store information about annotations in a centralized database, instead, I store information about annotations in web documents decentralized through out the web.
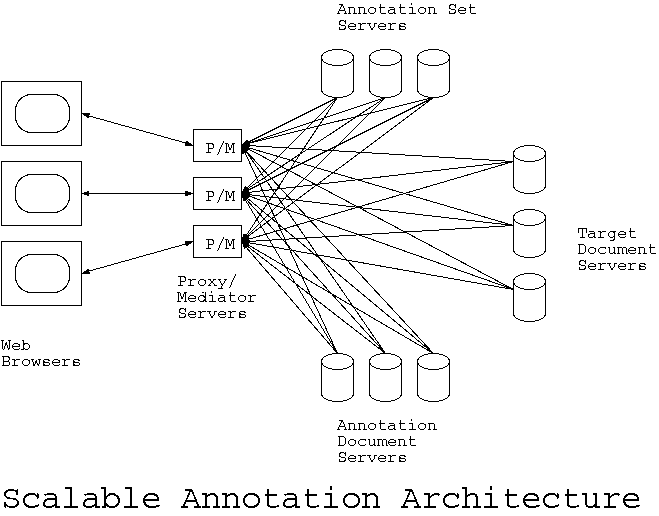
The proposed architecture for scalable annotations is shown in the diagram below:
In this architecture, target documents (defined below) are fetched through proxy/mediator servers (defined below) which are responsible for merging in additional annotation information before sending the merged information to the web browser for final display. Both the target documents and annotations are served up by standard web servers. Since annotations are full-fledged documents, they can be annotated just like a regular document. The annotation set server (defined below) is a standard web server with an associated annotation spider (defined below.) The annotation spider is responsible for visiting each of the annotation documents and building the annotation set index. The resulting annotation set index is represented as a structured set of HTML documents that are served up by a standard web server. The proxy/mediator servers know how to fetch target documents and read the structured annotation set document tree for each user set (defined below.) In fact, it is possible to implement proxy/mediator servers as a plug-in module to the ever popular Apache web server. This architecture does not require any modifications to the web browsers, but if people want to merge the proxy/mediator functionality into the the web browser, that is certainly feasible.
I have introduced some new terms that need to be defined:
The first concept I want to discuss is user sets. A user set is basically an end-user's instructions to a proxy/mediator server about what annotation sets to display and how to display the annotations contained therein. For example purposes, I have created an example user set. In this user set all of the information is encoded in HTML in a form that is both human and machine readable. There are three sections:
At this stage of the design, the exact syntax and semantics of user sets have not well specified. The only requirement that I have is that the syntax be extensible so that new lists, rules, and style elements can be added without requiring a flag day to update all of the proxy/mediator servers.
In order to permit an even exchange of ideas, it is important that annotations themselves can be annotated. This means that an annotation must be a full fledged HTML document with its own URL. It is possible to come up with annotation systems that do not have this property, but I am not interested in designing such an annotation system.
It is my opinion that I should be able to send the URL for an annotation to someone, and that someone should be able to easily identify the following:
The authoring of annotations is separable from the rest of the system design. As far as the system design is concerned, it does not matter how annotations are authored. However, a system that says `If you want to author an annotation, you are on your own.' is not likely to be as successful as one that provides some help. For this reason I will discuss three levels of annotation authoring support:
[Annotate] and the user
will be able to quickly and easily
fill in the rest of the annotation.
Once an annotation document standard is defined, it should be possible for some dedicated individual to add integrated annotation support to the Netscape Navigator open source code. Until then, it is necessary to provide some authoring support that does not entail quite as much implementation effort as direct integration into the web browser. It is fairly easy to implement a system based on CGI scripts and HTML forms that is functional, if not very pretty. The rest of this section walks through the CGI script based solution as a sanity check that it is doable.
A user would go through the following steps to use a CGI script based authoring tool:<Form Method="POST" Action="http://myhost/~myname/cgi/annote.cgi">The
To annotate this document, please click this button:
<Input Type="Submit" Name="Annote" Value="Annotate">
<Input Type="Hidden" Name="URL" Value="http://targethost/.../thisdocument.html">
<Input Type="Hidden" Name="User_set" Value="http://myserver/~myname/user_set.html">
<HR>
<HR>
</Form>
Action= specifies the machine
and CGI script to use for sequencing through the
remaining steps; this field ultimately comes from
the user's User Set. This form also has a couple
of hidden fields that specifies the URL of the
document to be annotated and the user's user set.
The double HR tags are are used to separate the
annotation header from the rest of the document.
[Annotate] button,
the CGI script brings up another version of the
same document which has an HTML 2.0 checkbox
next to each major chunk of text (e.g. paragraph,
heading, block quote, etc.) I have a mock up of
this page as well. In addition to selecting
text fragments, the user gets to select which
annotation set he/she wants to stick the ultimate
annotation into.
[Generate Annotation] button,
the annotation would be generated and stored
in the user's file system. Finally, the
CGI script will nudge the Web Spider on the
annotation set server to update its annotation
index.
Frames as they are currently designed are pretty annotation hostile, since they break the fundamental concept that each web document have a URL. I could rant and rave about what a bunch of idiots the HTML ERB (Editorial Review Board) were to let frames go through with such a flaw in them, but I was on the committee at the time, and well, we were a bunch of idiots. (Actually, I am being too harsh, there was some interesting politics going on at the time.) Anyhow, it does not matter anymore. Frames are here to stay and the standard for frames is not going to change any time soon. So the rest of this section is how to work around the problems caused by frames.
So what's the problem? Well basically, an annotation document should be stand on its own and reference the target document to be annotated via a hypertext link. The problem is that the target document may not display itself correctly unless it is fetched in the context of some frames. The proposed solution to this problem is for the annotation document to provide the frames environment for the target document. It does this by using a magic URL that is processed by a CGI script to bring up the correct page. The URL has the following syntax:
http://cgihost/cgi/frameurl.cgi?Frames={frameURL}&Name={frameName}&Target={targetURL}This is basically a standard URL which feeds three arguments to a CGI script. The
Frames=
argument specifies the top level frames document.
The Name= specifies the frame name
where the target document is to be displayed.
The Target= specifies the target document
URL. The CGI script read the three arguments,
fetches the frames document, substitutes the target
URL into the document in to the named frame and
returns the result. The web browser reads the
resulting document, forms up the frames, and displays
the target document. As I say, it is not very pretty,
but it will get the job done.
Why do it this way? Well, it has to do with copyrights and fair use and all that legal stuff. It is really attractive to make a copy of the frames document, edit it to point to the desired document, and point the annotation document at that. Unfortunately, the frames document is likely to be copyrighted. Making a copy of the entire document and making a small change to it is going to get somebody annoyed at you. By always going back to the original frames document and modifying it on the fly, we are back to the same legal status with inserting annotations on the fly. Finally, there is a good chance that the owner of the target document might choose to change the top level frames organization around a little, an we might still be able to cope with that; whereas if we have our own copy, everything might break pretty horribly.
The proxy/mediator server is responsible for merging annotations into target documents as they are pulled through the server. The proxy/mediator server goes through the following steps when merges in annotations:
The proxy/annotation server maintains an in memory data structure for each of the user sets that it has been asked to keep track of. Each of these user sets is given a time stamp, so that after an hour or so, the data structure will be declared idle and dropped, or it will be declared stale and refreshed. This internal data structure keeps track of all of the information contained in a user set -- namely,
The next data structure that the proxy/mediator keeps track of is the annotation sets. These are shared amongst all user sets. Thus, if five user sets reference the same annotation set, they will all point to the same annotation set data structure. As with user sets, there is a timestamp that keeps track of how long it has been since the annotation set information has been fetched. After an hour or so, the annotation set is either declared idle and dropped or stale and it is refreshed. An annotation set is basically one big happy nested data structure:
Searching an annotation set data structure for a matching annotation is just a repeated exercise of binary searching. It should be quite quick. Once a the proxy/mediator has located one or matching annotations, it can go back to the user set to find the rules and styles to use to merge the annotations.
The merging process is the standard tedious process of finding the matching fragments and inserting the user specified annotation link in.
{Talk about making the proxy/mediator an Apache server module.}
The annotation spider is the name given to the daemon process is responsible for building the target document index needed by the proxy/mediator server.
Basically, the annotation set consists of a whole bunch of annotation records where Each annotation record has the following information:
The annotation spider can be very batch oriented and rebuild all of the indices from scratch each time a new annotation added to the set, or it can be designed to support incremental update. The incremental update method will scale to larger annotation sets.
In order to add an annotation URL to an annotation set, an HTML form connected to a CGI script is used. The HTML form asks for the annotation URL name and optionally a user and a password. Upon submission, if appropriate, the user and password are verified, and the annotation URL is fetched. The annotation document is read, parsed, and the appropriate information is read out. If the annotation URL can not be reached, or it contains formatting errors, appropriate error messages are generated. If there are no formatting errors, the annotation is added to a queue of annotations to be added to the annotation set. Please note that the CGI script used for annotation authoring above, uses this same script.
The annotation spider takes each annotation from its in queue and inserts it into the annotation set HTML files. If an annotation matches any outstanding notification requests, a notification E-mail message is generated as well.
In addition to inserting annotations into the annotation set, the annotation spider is responsible for periodically scanning the existing annotations to see if any of them have gone away. Any time an annotation has gone away for a week or more, the annotation spider assumes that it will not be coming back and deletes it from the annotation set. Again, if the annotation matches any outstanding notification requests, a notification E-mail message is generated as well.
In order to keep, several replicated annotation sets synchronized, the master annotation set merely has to reliably transfer the insert and delete requests to the slave annotation servers.
I will just list the open issues below:
This section contains a number of scenarios of how to use an annotation system. The scenarios are listed in no particular order.
While the academic community has been quick to experiment with the web, when it comes to important issues, like publication in peer reviewed journals, the academic community has been a little slower in adopting web technology. The premise in this scenario is that in the future, people will publish peer reviewed papers using internet web sites instead of paper publication.
In this scenario, the rules are pretty straight forward. Members pay dues to support the journal. In return for paying dues, the members get the ability to see the journal papers 1 year prior to general release. After the 1 year has elapsed, the papers released to the general public. Non-members can get a copy of the paper before the 1 year has elapsed by sending a modest fee to the journal. The reason for holding back general publication for one year is to provide an incentive for people to sign up for the membership dues needed to run the journal.
In addition to publishing papers, the journal also publishes an annotation set. The annotation set policy is that any member can submit an annotation to the annotation set. The journal editors review each annotation prior to inserting it into the annotation set. The journal requires that each annotation be stored on the journal's web server to ensure that the annotations never get accidentally deleted.
In the collaborative editing scenario, a group of people is tasked with producing a finished document. Each draft of the document is published on a semi-regular basis. The collaborators attach annotations to the document that discuss issues that they have with the document. The document editor reads each version of the document and attempts to incorporate text from the annotations into the next document version. At the end of the whole process, there is the finished document along with a sequence of prior document drafts that contain the discussion lead up to the final draft. Thus, if a question arises about why something was written into the final document, it is possible to go back to prior drafts and read the annotations to jog people's memories.
The entire collaborative editing scenario does not have to be public. The document drafts and annotations can all be password protected and reside on a single machine.
In the United States, there are thousands of political action committees where each committee is engaged in advocating a list of issues of interest to the committee. It is frequently the case that there are two committees with pretty much opposite views. Each committee will have their own web site that provides materials that promote their issues. In addition, each committee will have an annotation set where they can annotate the other committee's site to point out inconsistencies, factual errors, and the like.
The annotation set policy for each committee is that that each committee is responsible for producing their own annotations on the other sites documents.
Interestingly enough, it is quite likely that people who interested in the issues enough to visit one committees web site are likely to visit both sites and both of their respective annotation sets. Who knows, maybe some of the more outrageous claims that are typically published in political materials will be toned down as a result of empowered voters being able to read the opposing views annotation sets. Furthermore, a newspaper writer who is on a tight deadline might be able to wade through the issues and come up with a more balanced viewpoint to publish in the local newspaper.
Speaking of newspapers, they may choose to provide an annotation set to their subscribers that allows their subscribers and editors to comment on the political action committees sites. The opportunities for political discourse abound!
FAQ stands for Frequently Asked Questions. The concept of a FAQ was popularized on internet news groups where the same questions came up again and again. The solution to the problem was for someone to volunteer to produce a collection of frequently asked questions and post it to the news group every other week.
The problem with FAQ's is finding that person that wants to dedicate a fairly substantial amount of time to task of organizing the FAQ. This scenario proposes an alternative method. Basically, the FAQ organizer is responsible for producing a list of questions. This list is posted somewhere along with an open annotation set for attaching answers to the questions. Thus, the annotation set policy is that anybody can contribute to the set with the only proviso being that the FAQ editor can delete annotations that are inappropriate for the news group.
As the answers fill in, other members can post summary annotations that try to aggregate the results of previous annotations. A user set can be set up so that annotations of type summary are given precedence of other non-summary annotations.
The net result of such a structure is that the task of producing the FAQ has been off loaded from the shoulders of one person. A well edited and maintained FAQ is an extremely useful document; however, the number of people who seem to be willing to sign up for the task of generating and maintaining a FAQ also seems to be declining. The net result is fewer and fewer up to date FAQ's; perhaps FAQ generation via annotation sets will reverse this trend with only a small overall reduction in content quality.
This scenario is a bit of a stretch. Basically, one of the biggest complaints about network news groups is that the same issues keep cropping up as new members join and ask the same questions. One strategy for dealing with this is the aforementioned FAQ's. The real problem is that eventually all network news postings expire and nobody can refer back to them. One solution is the solution for some start-up company to form with the goal of keeping all network news group postings; Deja News is one such company.
An alternative strategy is to use annotation sets. Basically, the concept is that there is one site where people post their original postings in chronological order. There postings are in the form of annotation documents. The responses to the original postings are annotations as well.
The advantages of using annotation sets are 1) scaling and 2) the newsgroup history hangs around a lot longer. The disadvantages are that people can alter and delete their postings. Thus, over time the newsgroup record would become fragmented.
What started all of this of was the problem of finding back links (references) to documents. A back link is basically a hypertext link back to every publicly available document that refers to a target document. Can annotation sets be used for this problem? The answer seems to be `probably not'. As annotation sets are currently structured, a complete back link target document index would be of gargantuan proportions. While one could imagine someone who tries to build and maintain such an index, it would be quite hard. The alternative solution already adopted by the CritSuite tools is to simply provide a button that can be pushed to query one of the search sites like Alta Vista to search for back links.
In addition to providing a button at the bottom of the page, the proxy/mediator could instead insert a .gif counter that lists the number of back links. That way the page could be displayed while in the background the proxy/mediator went off the notoriously overloaded search engine and did a back link query on the page. Of course, this will simply increase the load on the search server; so, this is probably not such a hot idea.
Companies spend millions upon millions of dollars (or other currencies) to establish brand name recognition. For generic products, like toothpaste, people seem to be willing to pay a little more for the brand name product. For less generic products, like cars, the branding is used to establish an image.
In this scenario, there is a company, which I'll call AlterBrand, that provides a public alternative brand annotation set. Let's assume that there are two companies -- MajorBrand and MinorBrand. The MajorBrand company expends large amounts of money to establish a brand name. Conversely, the MinorBrand company chooses not to spend the money to establish a brand name and passes the reduced advertising costs onto their customers in the form of lower product costs. MinorBrand pays AlterBrand for the privilege to place annotations on MajorBrand's product pages. A user of the AlterBrand annotation set will visit MajorBrand's web pages to get links to the corresponding products offered by other vendors.
It should be noted that companies that spend big bucks on brand name advertising are not going to be amused by the AlterBrand company. The MajorBrand company is likely to retaliate against AlterBrand. They may choose to make all of their web content dynamic so that the proxy/mediator is not able to attach annotations to the pages that make of the MajorBrand web site. In addition, MajorBrand probably has a whole bunch of lawyers on retainer who would set to the task of suing AlterBrand. If the courts do not give provide satisfaction, MajorBrand is likely to bribe, I mean, make major campaign contributions to, the political system to pass legislation to make AlterBrand's annotation set illegal. AlterBrand is likely to retaliate by going off shore. I have this image of a boat sitting in the middle of the Pacific somewhere with a satellite dish and the AlterBrand annotation set server. Of course MajorBrand would probably hire some country whose military is for sale to sink the boat with a torpedo. If MajorBrand does not hire France to do the job, the AlterBrand boat may actually get sunk.
The comment I have about brandname bootlegging is that it is likely to get a lot of people with a lot of money really annoyed. It may be appropriate to head this controversy off by providing a way for companies to put up a `No Annotations Here' marker on there web site. This could be similar to the robots.txt file that already used to limit the activities of web spiders. The down side of have a no annotations file marker is that there are some sites out there that really should be annotated.
(I am not a lawyer; I expect a lawyer could explain how to apply annotations to the law field way better than I can.)
In the United States and other countries that use the same basic legal system, laws that are passed by the legislative branch of the government continually undergoing a process of reinterpretation via case law. Each time a law is used to determine the outcome of a particular case, that case becomes associated with the law as an example of how to apply a law. Over time a law will have a set of legal precedents that show how a number of different court rooms have interpreted a particular law.
Lawyers spend a significant amount of time trying to understand the relevant case law when they are preparing a case for trial. They would probably love to use a system where all laws were published on the web, and any cases that established case law would be attached to appropriate laws along with discussion summaries.
Currently, the United States is a constitutional republic where citizens elect representatives to form their government. In theory, the elected representatives represent the majority view of their constituents. In practice, the representation is a uneven in that interests that have more money appear to get more representation.
Can annotation systems help offset the uneven representation? What would happen if before a representative cast a vote on a piece of legislation, the representative has a statistically significant sample from his or her district that indicated how the constituency thought the vote should go? How big would the sample constituency have to get before the representative started to worry about voter backlash at the next election?
The proposal here is to require that laws be published in their final form one week prior to the vote; this is in contrast to the current practice where sometimes laws are being rewritten after they have been voted on. The final laws would be published to the Net in HTML format. In the week before the vote, the constituents of a representative's district would have the opportunity to send preference to their representative via E-mail. In addition, to prevent fraud, the constituents would send their preferences to non-partisan organizations that separately tally the preferences. The totals would be tabulated one day before the vote so that the representative will have the information before the vote. At the extreme point where 100% of a districts in a district participate in the system, this approaches a democracy (i.e. all people vote directly on all laws.)
There are a lot of details to be considered before such a system would actually work. The biggest problem is that most people have no where near the amount of time required to investigate every law and decide whether they are for or against it. (That is why republics have historically been more practical than democracies.) The good news is that there are thousands of political action committees how spend all of their time doing pretty much nothing else but look at laws and try and get them passed or defeated. So instead of citizens trying to figure out each law, the citizens would rely on their political action committees to do the research. Thus, a citizen would find identify a list of political action committees that represent his or her views. The political action committees broadcast their preferences and the citizen collects the preferences from all of his or her political action committees and forwards the preferences on to their representative. Sometimes, two political action committees on a citizen's list will sometimes come to opposite recommendations on a piece of legislation, the citizen has to decide how to resolve such conflicts. One possibility is that the citizen could look at the conflicts on a case-by-case basis. After a while, the citizen will discover that they are usually choosing one political action committees preferences over others on his or her list. There are many other issues that need to be resolved as well, but I will pass on discussing them for now.
Hopefully, this has scenario somewhat interesting, but where do annotation systems come into the picture? In the scenario described, in section 3.3, Political Action Committees, annotation sets are used to promote the political discussion of the legislation. In addition, how do preferences get sent to the representative? Well, it may be appropriate to design a whole new protocol, but really all that is necessary is to have citizens post their preferences as annotations. The representative would have an annotation set that has a policy that any registered voter in the representative's district can post annotations to it. The annotation types would be support, oppose, and abstain. Right before the final vote, the annotation set can be scanned to count the support, oppose and abstain annotation types attached to the piece of legislation being voted on. The vote tally is done carefully to ensure that a registered voter only gets one. vote.
There is a mountain of details an issues that need to be worked through on this scenario. Hopefully, you can see that annotation sets might play a significant role in the final system.
The fundamental design goal of this annotation system is this scale to thousands of annotations sets and millions of users. The reason why I feel that this design will scale is because there is no centralized bottleneck in the system. The web browsers, proxy/mediators, annotation sets, annotation documents, and target documents are spread all over the net. If a particular proxy/mediator becomes overloaded, some new hardware can be rolled in, and the load can be split across the new hardware. The same is true of the annotation set servers, they can be replicated to deal with overload situations. Please note that I have very deliberately tried to ensure that the annotations them selves do not have to be stored on the annotation set servers. Thus, each time a user follows a link in an annotated document, they go directly to the machine that contains the annotation without having to visit the annotation set server. So, while I won't know for sure how scalable this architecture really is until it is implemented